Table des matières
L’objectif de cet épisode 1 est de parcourir les concepts proposés par GIT, à travers une session de développement. Nous commencerons à voir des commandes, du vocabulaire, sans rentrer trop dans les détails, qui seront ensuite donnés dans les épisodes suivants.
Historique
On peut classer GIT dans la catégorie des gestionnaires de versions, ou VCS (Version Control System). L’objectif est de gérer les différentes versions d’un code source (ou d’autres fichiers), durant l’ensemble de son cycle de vie.
GIT a été créé en 2005 par Linus Torvalds, pour le développement de noyau Linux. L’équipe de développeurs du noyau Linux utilisait depuis plusieurs années un logiciel de SCM (Source Code Management) appelé BitKeeper. C’est en rendant, le code de BitKeeper publique, qu’est né Git-SCM.
Il existe deux types de gestionnaire de versions
- Les gestionnaires centralisés (Centralized version control system - CVCS),
- Les gestionnaires distribués (Distributed / Decentralized version control system - DVCS).
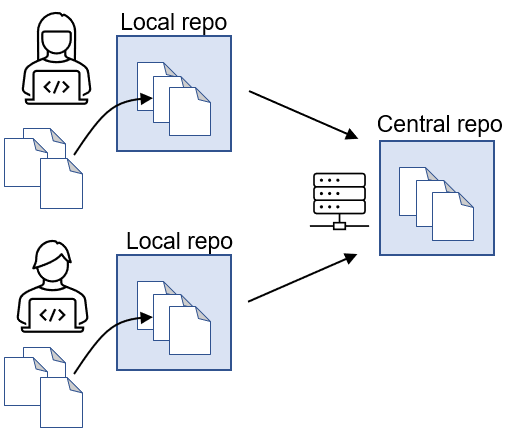
Contrairement à la majorité de ces prédécesseurs, GIT est un gestionnaire distribué. Chaque développeur dispose sur sa machine de son propre dépôt de source (repository), mais chacun garde la possibilité de “pousser” son code vers un dépôt distant / centralisé (remote repository).
1. L’installation et configuration
Démarrons donc notre périple : nous avons une application à développer, ou du contenu à écrire, et nous souhaitons démarrer ce projet avec un outil de versionning. Nous sommes pour l’instant sur un ordinateur individuel.
La première étape est d’installer l’outil GIT lui-même. Il faut donc
- Télécharger l’outil depuis le site Git ,
- Installer l’outil (je ne détaille pas cette étape), en prenant les options par défaut.
Une fois le produit installé, il n’y a quasiment pas de configuration à faire, l’outil peut être utilisé directement. Il est cependant recommandé de configurer notre nom (ou un pseudo, et notre adresse de messagerie, et l’éditeur que l’on souhaite utiliser.
| |
Une liste de configurations pour un grand nombre d’éditeurs est disponible sur le site de GIT
2. Création d’un dépôt
Les outils sont prêts, passons à l’étape suivante, en créant le projet proprement dit :
| |
Si l’on regarde le contenu du répertoire <nom du projet>, on s’aperçoit que la commande à créer un répertoire .git.
Une autre façon de faire est de “cloner” un projet existant, qui se trouve sur un dépôt distant :
| |
La syntaxe est git clone <adresse des dépôts distants> <répertoire>. Le répertoire indiqué, désigne le répertoire dans lequel sera téléchargé le code source.
La commande va télécharger tous les éléments se trouvant dans un dépôt distant (Github, Gitlab, SourceForge, …).
Avant d’aller plus loin, nous avons quelques explications à donner :
- En tant que développeur, nous allons créer / éditer / effacer des fichiers, qui stockés dans une arborescence,
- GIT va “traquer” ces changements, et les stocker dans une sorte de structure parallèle, que l’on appelle dépôt.
Le point de départ est donc une arborescence de fichiers. Dans cette arborescence, nous avons des fichiers qui peuvent être
- Non-suivis (untracked) : ces fichiers ne sont pas suivis par GIT, et ne peuvent donc pas être manipulés par l’outil,
- Suivis (tracked) : GIT est capable de détecter chacune des modifications de ces fichiers (grâce à un mécanisme de checksum),
- Modifiés (modified/dirty) : on retrouve ici, l’ensemble des fichiers qui ont été modifiés, mais qui n’ont pas encore été indexés,
- Indexés (staged) : Il s’agit de fichiers qui ont été modifiés, et placés dans une zone particulière que l’on pourrait appeler zone de transit (staging area), en attente de validation (commit)
- Validés (commited) : les fichiers validés sont ceux dont nous souhaitons figer / conserver les modifications.
GIT considère trois zones de stockage pour ces fichiers : Le working directory (répertoire de travail), la staging area (zone transitoire), et le Git repository (dépôt Git).
Bien comprendre ou se trouvent les fichiers que l’on souhaite manipuler, est essentiel pour bien utiliser GIT.
La figure figure 3 résume ce qu’il s’est passé pour l’instant, avec notre commande git init.

3. Le processus de base
Le processus très simplifié avec GIT est décrit dans le schéma suivant :
- Le développeur crée, édite, efface, déplace des fichiers,
- Quand une série de modifications lui semble cohérente, et stable, le développeur place les fichiers dans l’index (la zone staging),
- Il peut alors vérifier l’ensemble des modifications effectuées,
- Avant de réaliser les commits nécessaires, en une seule ou plusieurs fois.
- Le développeur repasse alors à l’étape 1.
Pour ces étapes, nous utilisons principalement deux commandes : git add pour pousser les modifications dans la zone staging (indexation), et git commit pousser les fichiers dans le dépôt (validation) :
En itérant le processus précédent, nous obtenons la figure 5 :
Dans la figure 5, HEAD est le pointeur vers le dernier commit, ou plus exactement, vers le parent du prochain commit.
4. Les branches
Le processus décrit précédemment est linéaire. Mais lors d’un développement, nous pouvons avoir besoin
- De mettre de côté le code en cours, pour explorer de nouvelles pistes, entamer une phase de développement un peu plus longue que d’habitude,
- D’arrêter le développement en cours, pour corriger un bug, et donc développer un patch,
- De développer une nouvelle fonctionnalité en parallèle du développement en cours.
C’est là que la notion de branche entre en jeux.
Création d’une branche
Par défaut, un dépôt possède une branche principale unique qui s’appelle main (précédemment master). Mais nous pouvons
- Créer des branches grâce à la commande
git branch <nom de la branche>, - Rendre une branche active :
git checkout <nom de la branche>.

Même s’il ne se passe finalement rien, on commence ici, à mieux comprendre le rôle du pointeur HEAD : ce pointeur indique le parent du prochain commit. Dans le cas de la Figure 5, nous étions sur la branche main, donc le prochain commit sera sur cette branche. Sur la Figure 6, après le checkout, HEAD est attaché à la nouvelle branche feature. Le prochain commit s’effectuera sur la branche feature.
Développement
Continuons notre développement
Dans la Figure 7, nous faisons progresser notre développement en suivant deux branches : main et feature. Nous avons bien une version v4 dans la branche main, et une version v3 dans la branche feature, et donc des développements qui peuvent continuer leurs évolutions en parallèle.
A noter qu’en général, nous n’effectuons pas directement de développement dans la branche main, mais dans des branches annexes.
Fusion de deux branches
A un moment donné, si nous sommes satisfaits des développements de la branche feature, nous pouvons les intégrer à la branche main. On parle de fusion de branches (merge). Lors d’une fusion, GIT va intégrer toutes les modifications contenues sur chaque branche dans une seule et même arborescence.
Le processus de fusion habituel est
- On se place d’abord sur la branche qui va recevoir toutes les modifications (dans notre cas
git checkout main), - On effectue la fusion :
git merge feature, - A partir de ce moment, toutes les modifications de la branche
featuresont intégrées à la branchemain, nous pouvons donc effacer la branchefeature.
L’opération de fusion créé un nouveau commit, qui a deux parents (dans le cas d’un true merge).
La fusion décrite correspond à l’intégration des modifications liées à une branche, dans une autre. Il existe d’autres méthodes permettant de remplacer une partie des modifications d’une branche, par les modifications effectuées dans une autre.
Gestion des conflits
Une fusion correspond à l’intégration de toutes les modifications effectuées sur les deux branches que nous souhaitons fusionner. GIT est capable d’identifier les modifications dans les différents fichiers, et de les agréger. Dans certains cas, cependant, GIT ne peut pas gérer certains “conflits”, qu’il faut alors résoudre manuellement.
Pour cela GIT interrompt le processus de fusion, et ajoute des marqueurs dans les fichiers à fusionner. Nous devons éditer les fichiers manuellement afin de résoudre ces conflits. Cette méthode est peu pratique. Heureusement, il existe des solutions plus ergonomiques, GIT étant intégré à un grand nombre d’environnements de développements.
5. Les dépôts distants
Nous arrivons à la fin de notre journée de développement. Puisque nous travaillons en équipe, il est temps de partager notre travail avec les collègues. Pour cela, nous allons “pousser” tous les commits d’une branche vers un dépôt distant :
| |
La commande git push va envoyer vers le dépôt distant désigné par origin, l’ensemble des modifications effectuées dans la branche feature. Vos collègues développeurs vont donc pouvoir voir votre code, et l’utiliser.

Fin de l’épisode 1
Cet épisode nous a permis de voir les grands principes d’utilisation de Git : Nous venons de voir notamment, la définition d’un dépôt, les trois zones de stockage, la notion de branche, ainsi que les dépôts distants.
La figure 11 résume les commandes utilisées dans cet épisode :