Pourquoi un workflow ?
Lorsque nous commençons à utiliser GIT, nous avons tendance à nous concentrer sur les commandes, et leurs conséquences. Cependant, maîtriser les commandes ne suffit pas à éliminer intégralement toutes les erreurs, surtout lorsque nous travaillons à plusieurs sur le même code. Il faut donc une méthodologie, dont les finalités principales sont (pêle-mêle)
- Optimiser le travail de chaque développeur,
- Favoriser les développements en parallèle,
- Permettre, et faciliter le travail en équipe,
- Eviter les conflits lors des merges (merge hell),
- Produire un historique de développement clair, facilement lisible par vos collègues (et par vous-même),
- Rapprocher le développement et la gestion de projet.
Un workflow doit également faciliter le cycle de vie du développement, et du déploiement des applications:
- Faciliter les revues de code,
- Permettre l’enchaînement des développements, des tests, et des mises en production,
- Le tout de façon complètement automatisée.

Préambule
Avant de démarrer la description de nos workflows, je vais aborder quelques concepts qui nous serviront un peu plus tard pour comprendre les subtilités de certaines méthodes.
Etiquettage / les tags
GIT offre la possibilité d’attacher des étiquettes à un commit. Cela permet, entre autre, de marquer des états de publication.
Commençons par le plus simple: lister des étiquettes
| |
Il existe deux types d’étiquettes: les étiquettes légères (lightweight), et les étiquettes annotées (annotated).
- Une étiquette légère n’est qu’un pointeur vers un état du code (un commit),
- Une étiquette annotée contient un certain nombre d’informations comme le nom de l’auteur, son adresse mail, une date, un message, … En outre, ces étiquettes peuvent être « signées », et vérifiées avec GPG (GNU Privacy Guard).
Pour créer une étiquette légère, il suffit de spécifier l’étiquette
| |
La création d’une étiquette annotée se fait de la façon suivante:
| |
Nous pouvons afficher une étiquette annotée avec la commande git show
| |
Par défaut, la commande git push ne propage pas les étiquettes d’un dépôt local vers un dépôt central. Il faut donc le faire explicitement:
| |
Si vous avez plusieurs tags à partager, la méthode la plus simple est d’utiliser
| |
Les versions
La notion de release (version) n’existe pas dans GIT, mais j’en parle ici rapidement, car elle est parfois confondue avec la notion d’étiquette.
Une version est une façon de rendre votre développement disponible auprès des utilisateurs, sous une forme « packagée »
Sans cette notion de release, un utilisateur souhaitant utiliser vos développements, devra télécharger le code. Avec la notion de release, l’utilisateur peut
- Télécharger le code,
- Télécharger des fichiers contenant une version “compilée” de votre application (quelque chose de prêt à l’emploi),
- Accèder à une description de la version (release note).
Les versions s’appuient sur les étiquettes pour désigner le code concerné.
La création d’une version s’effectue facilement, via l’interface de GITHUB.
Etape 1: dans l’écran principal de votre dépôt, cliquer sur Release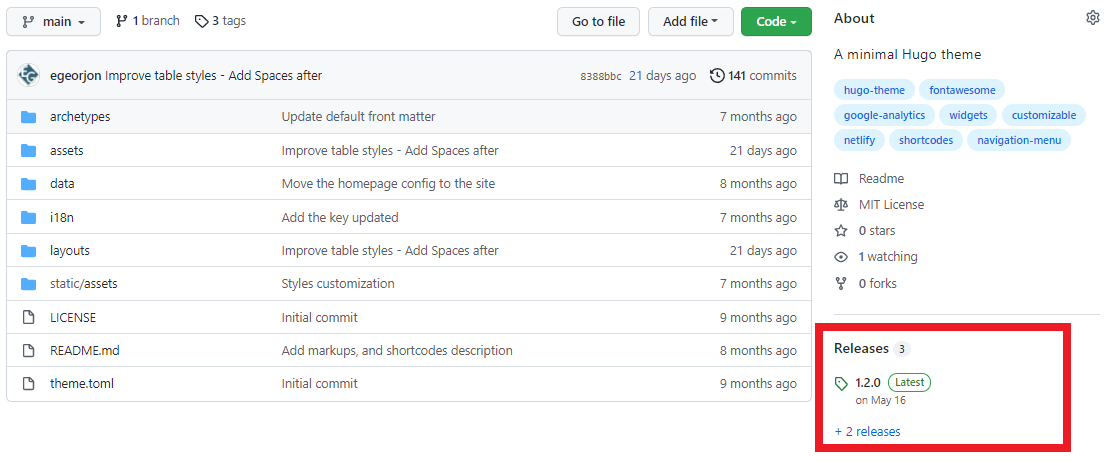
Etape 2: Github affiche alors la liste des versions disponibles dans le dépôt.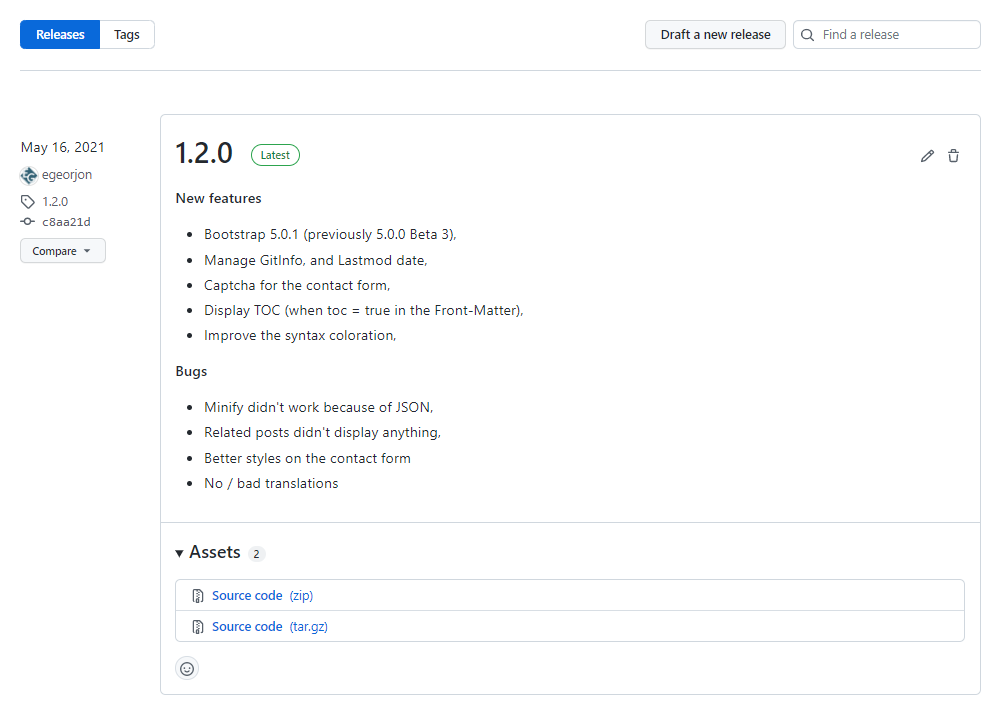
Etape 3: Cliquer sur Draft a new release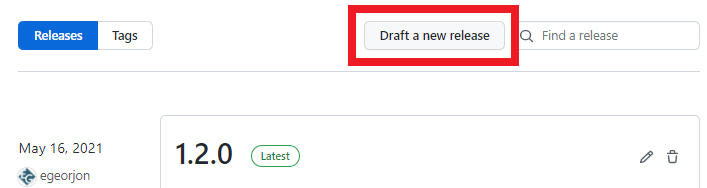
Etape 4: Choisir un tag, ou en créer un nouveau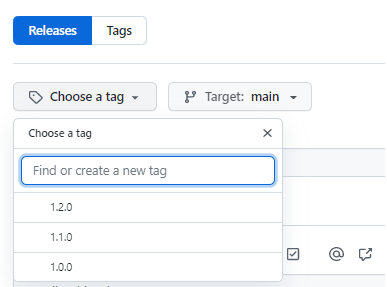
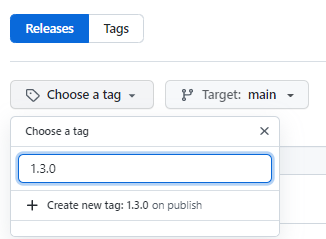
Etape 5: Compléter les informations requises
- Le nom de la release,
- Une description (la release note),
- Ajouter des binaires si besoin (compilation de votre code, par exemple)
- Si l’utilisateur doit considérer cette version comme une version de production ou non,
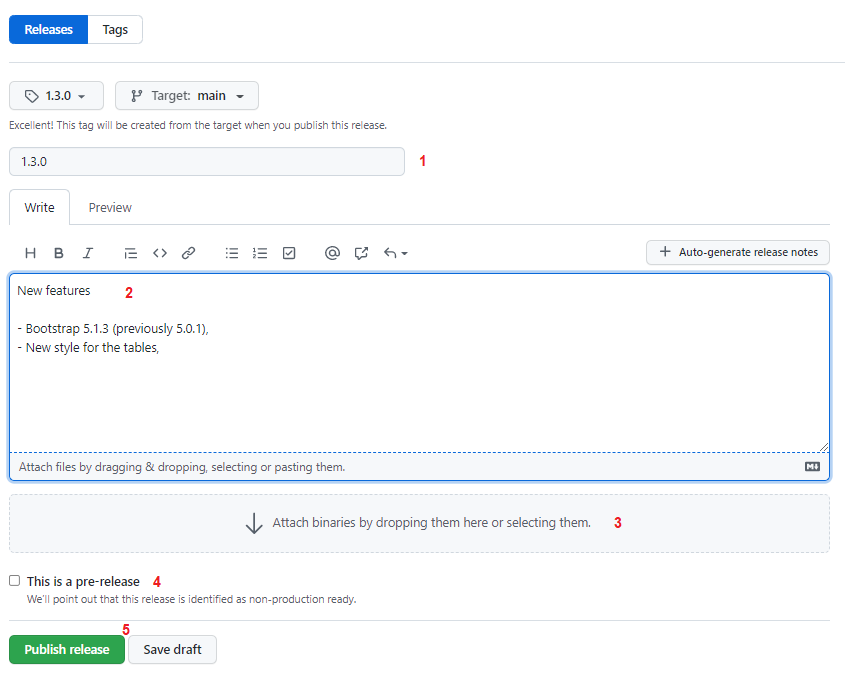
Etape 6: Publier cette release ou la sauvegarder en mode brouillon (point de la figure 8)
Les pull requests
Comme pour les releases, les pull requests ne sont pas un concept GIT à proprement parler. Cette fonction a été popularisée par GitHub, puis adoptée par d’autres outils, comme GitLab (merge-request).
Un pull request est un outil permettant à des développeurs (appelés contributeurs), d’apporter des modifications à un projet sous le contrôle d’un groupe de personnes chargées de gérer le projet (les mainteneurs).
Un pull request n’est pas une simple commande équivalente à un git merge. C’est un ensemble d’outils permettant
- de faire une demande d’intégration de certaines modifications dans une branche spécifique,
- de discuter de ces modifications, de gérer les conflits possibles,
- de faire “valider” cette demande,
- et, finalement, de réaliser le merge.
Dans l’image suivante (figure 9):
- La demande du développeur, avec les explications, le lien vers le code (le commit),
- Les vérifications automatiques de Github, avec le résultat (ici pas de conflit),
- La zone de dialogue entre les validateurs, et les développeurs.
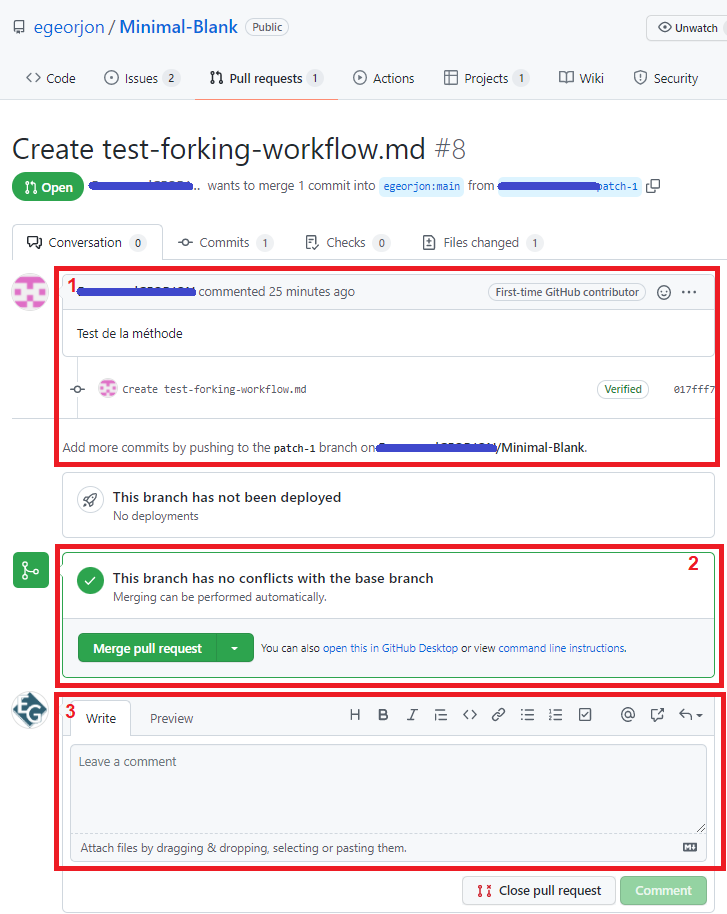
Nomenclature
Dans tout le reste de l’article, j’utiliserai la nomenclature, et le code couleur suivant:

Gitflow
GitFlow est un méthode créée par Vincent Driessen en 2010. Même si elle ne semble plus être dans l’air du temps, cette méthode est toujours très largement utilisée aujourd’hui, avec de multiples variantes.
Principe
Gitflow fait un usage intensif des branches, en suivant les étapes de développement d’une application.
Pour expliquer la méthode, je vais reprendre le plan de l’article de Vincent Driessen (en anglais) que je vous invite à consulter.
La méthode s’appuie sur deux branches principales (figure 11):
- La branche principale (main ou master) pointe sur le code tel qu’il est en production,
- La branche développement (develop) pointe sur les dernières évolutions du code, qui seront utilisées pour la construction des prochaines versions. Cette branche peut être également appelée branche d’intégration. C’est à partir de cette branche que sont effectuées les contructions / compilations quotidiennes (nightly build).
La fusion de la branche développement vers la branche principale correspond par définition à une nouvelle version (new release).

En plus des branches développement et principale, la méthode propose trois autres types de branches
- Les branches fonctionnalités (features),
- Les branches versions (releases),
- Les branches correction (hotfix).
Les branches fonctionnalités (features) sont dédiées au développement d’une ou plusieurs fonctionnalités, et sont amenées à être fusionnées dans la branche développement. L’article indique que ces branches peuvent rester au niveau des dépôts locaux, et ne sont pas poussées dans le dépôt central (Feature branches typically exist in developer repos only, not in origin).
L’option --no-ff est recommandée lors du git merge pour garder un historique de l’opération.

Si une fonctionnalité est développée par plusieurs intervenants, les branches correspondantes doivent être partagées (comme pour la figure 13). L’intérêt de cette variante est de gérer la fusion de ces branches feature, à travers un pull request.
Les branches versions (releases) sont utilisées pour la préparation d’une nouvelle version de production. Ces branches
- sont créées à partir de la branche développement (develop), lorsque cette branche reflète ce que l’on veut mettre en production,
- ne doivent servir qu’à réaliser de petits ajustements, avant la mise en production.
La création d’une branche version correspond
- A l’attribution d’un numéro de version (tagging),
- A l’arrêt des développements pour cette version (sauf ajustements mentionnés précédemment),
- Au début des développements de la version suivante (dans la branche développement).

Les branches correction (hotfix) sont utilisées pour intervenir rapidement sur une version de production pour corriger un bug urgent. Cette branche est créée à partir de la branche principale. La création d’une branche spécifique à la gestion des bugs urgents permet
- de démarrer rapidement la correction à partir du code déployé en production,
- de ne pas interférer sur les développements en cours ( branche développement).

Une fois les corrections prêtes, elles doivent être ré-intégrées dans
- la branche principale pour corriger la version actuellement en production,
- la branche développement pour inclure la correction de bugs dans le développement en cours,
- ET, dans la ou les branches versions si elles existent au moment de la correction.
Le flow global
Dans sa globalité, la méthode se présente sous la forme suivante (figure 16):

Motivation
La méthode Gitflow multiplie les branches, afin d’isoler chacun des flux de travail
- Le travail de correction ne se fait pas dans la branche de développement,
- Le travail de mise en production s’effectue dans des branches spécifiques (release), et pas dans la branche develop, ni dans la branche main.
L’avantage est que chacun de ces flux peut se faire en parallèle: des équipes peuvent travailler sur de nouvelles fonctionnalités, sans interférer avec celles qui travaillent à la mise en production de la prochaine version.
La méthode présente deux inconvénients potentiels:
- La complexité liée à la gestion des branches, qui peut générer un historique de commits difficilement lisible,
- Les problèmes de merge: plus les développements « silottés » sont longs, plus les fusions sont complexes (merge hell).
Feature branch
Principe
Comme son nom l’indique cette méthode consiste à créer une branche par fonctionnalité à développer. Cette méthode peut-être considérée comme une version simplifiée de la méthode Gitflow. La méthode systématise le partage des branches features, et l’utilisation des pull-request pour gérer la fusion entre ces branches, et la branche principale.
Chaque développeur
- Clone le projet sur son poste,
- Crée une branche pour développer une nouvelle fonctionnalité,
- Effectue des commits sur la branche créee,
- Envoie ces commits vers le dépôt cental (
git push), sur la branche créée précédemment, - Crée un pull request en demandant la fusion entre la branche liée à la fonctionnalité, et la branche principale.
Le (ou les) validateur
- Traite les pull request,
- Fait intervenir des membres de l’équipe pour des revues de code, ou des tests,
- Gère les conflits qui peuvent apparaître lors de la fusion des deux branches.

Motivation
Comme pour GitFlow, le principe général de la méthode Feature Branch est de paralléliser les développements des différentes fonctionnalités pour les intégrer au moment voulu.
Variante
Il existe une variante de cette méthode, utilisant une branche supplémentaire appelée développement, afin de « protéger » la branche principale. Cette variante se rapproche encore plus de la méthode Gitflow.

Trunk-Based Development (TBD)
Motivation
La méthode Trunk-Based Development (TDB) part de deux principaux constats:
- Le travail par branche à tendance à « isoler » les différentes équipes de développement: s’il y a bien une collaboration entre les développeurs d’une même équipe, une communication entre les équipes n’est pas obligatoire / nécessaire. Il n’y a donc pas d’échanges entre les équipes.
- Effectuer un développement long au sein d’une branche, rend les fusions plus complexes (merge hell).
Principe
Les concepts liés à la méthode TDB sont donc
- Réduire autant que possible l’utilisation des branches,
- Réduire la taille des « lots » de développement,
- Augmenter la fréquence de livraison (l’intégration des nouveautés à la branche principale).
Dans sa version la plus réduite, la méthode est la suivante (figure 19):

Chaque développeur
- Clone le projet sur son poste,
- Effectue des commits fréquents sur la branche principale,
- Envoie ces commits vers le dépôt cental (
git push), toujours sur la branche principale.
Le gestionnaire de version
- Est le seul a pouvoir travailler en dehors de la branche principale,
- Eventuellement créer des versions (release),
- Génère des branches par version (release branch).
A noter que pour cette version simplifiée, les développeurs poussent directement les modifications sur la branche principale:
- Il n’y a donc pas de pull-request, donc pas de contrôle de ce que les développeurs intégrent,
- Chacun des développeurs doit gérer, avec ces collègues, les conflits potentiels, lors des
git push.
Derrière les principes généraux décrits un peu plus haut, se cachent donc d’autres principes permettant à la méthode de fonctionner:
- Collaboration / synchronisation étroite entre développeurs,
- Il faut des développements courts (pas plus de quelques heures), des commits et des push fréquents,
- Le code dans la branche principale doit être, à tout moment, être utilisable pour la production: Il faut s’assurer qu’aucun commit ne génère de problème lors des phases de compilation (never break the build, keep the trunk release ready)
Variante
Au quotidien, la méthode décrite précédemment fonctionne parfaitement pour des équipes réduites de quelques personnes. Pour des équipes de développeurs plus importantes, ou si les équipes souhaitent organiser des revues de code, la méthode autorise l’utilisation de branches, similaires aux branches de fonctionnalités (feature branches), déjà évoquées avec les deux méthodes précédentes. Pour respecter l’esprit de la méthode TBD, la durée de vie des branches doit rester courte.

Forking workflow
Cette méthode diffère des autres méthodes citées jusqu’à présent. Pour ces méthodes, nous avons en effet, utiliser une approche basée sur la gestion des branches (voir chapitre 4 de cette série).
- Nous avons un dépôt central,
- Les développeurs clonent ce dépôt sur leur poste de travail (dépôt locaux),
- Ils peuvent créer des commits, et des branches,
- Qu’ils poussent ensuite sur le dépôt central.
Dans le cas de projets vastes et complexes, le contrôle d’accès aux branches est complexe. Dans certains cas, les développeurs n’ont pas d’accès en écriture au dépôt. Les méthodes précédentes ne sont donc pas applicables.
L’idée est donc de passer par un dépôt intermédiaire:

Cette méthode, très utilisée dans le domaine des projets opensource, consiste à mettre en place la structure de dépôts, de la façon suivante:
- Créer un nouveau dépôt (dépôt de fork), copie du dépôt d’origine (dépôt de référence),
- Cloner ce nouveau dépôt sur son poste de travail,
- Ajouter au dépôt local, le dépôt de référence comme dépôt distant,
La création du dépôt de fork, peut se faire, par l’intermédiaire de l’interface de Github, ou Gitlab
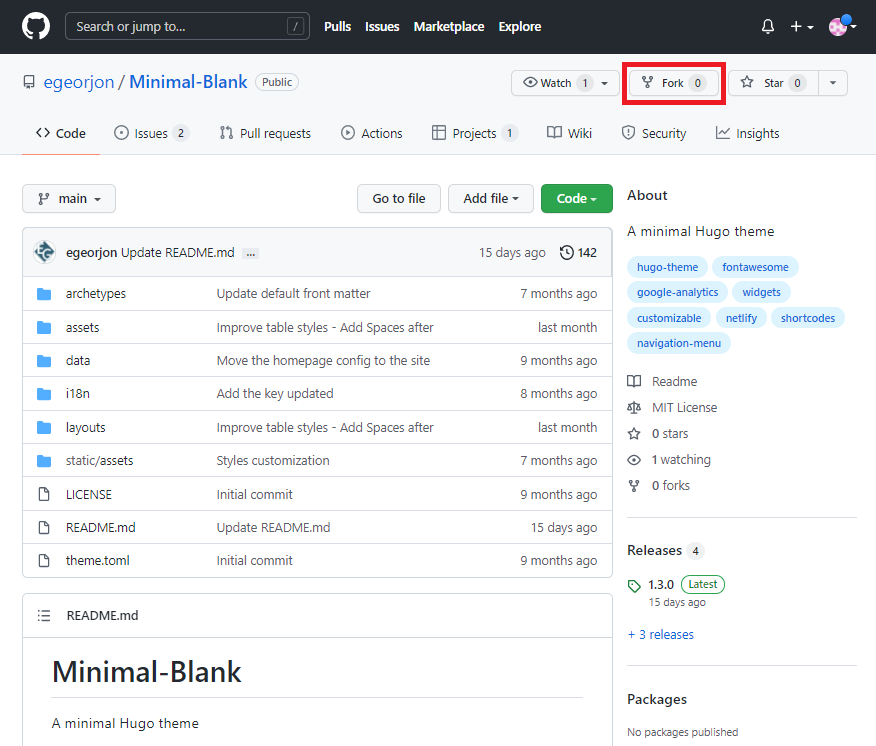
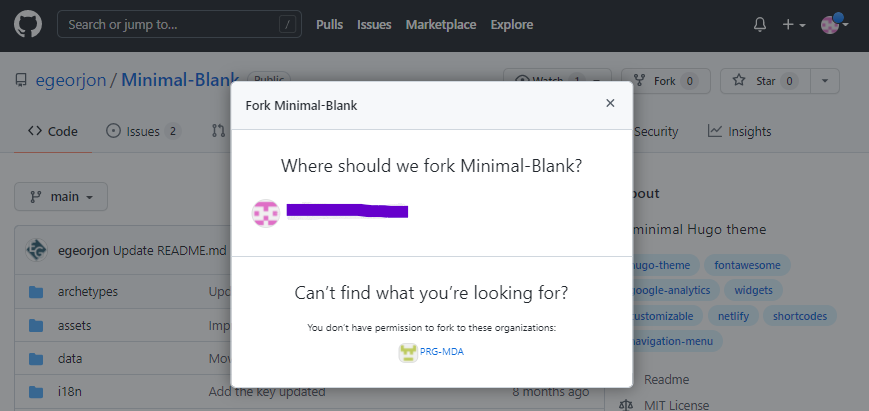
L’ajout du dépôt distant se fait par la commande
| |
Le mode d’utilisation de ces dépôts est la suivante:
- Mises à jour régulières du dépôt local, à partir du dépôt de référence (
git fetch / git pull), - Création de branches et de commits (en local),
- Pousser de ces branches du dépôt local, vers le dépôt de fork (
git push), - Lancer un pull request pour demander l’incorporation des branches dans le dépôt de référence.

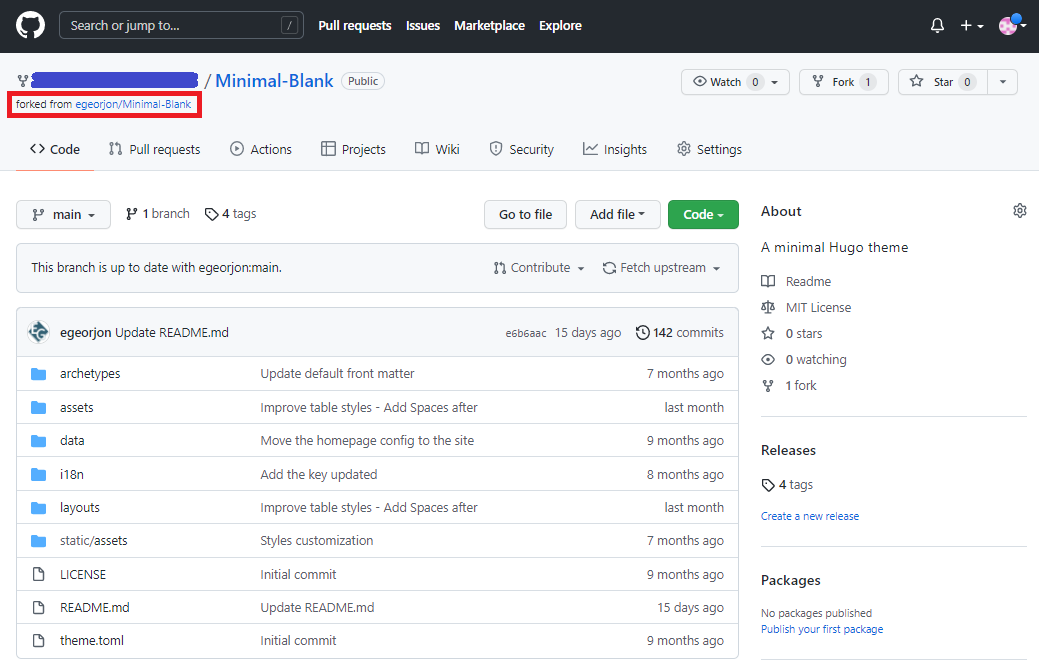
Prenons un exemple avec un de mes dépôts:
- Dépot de référence: https://github.com/egeorjon/minimal-blank ,
- Dépôt de fork: https://github.com/ … …/minimal-blank,
A partir de là, je crée un fichier supplémentaire dans le dépôt de fork (dans la branche main), et j’effectue un commit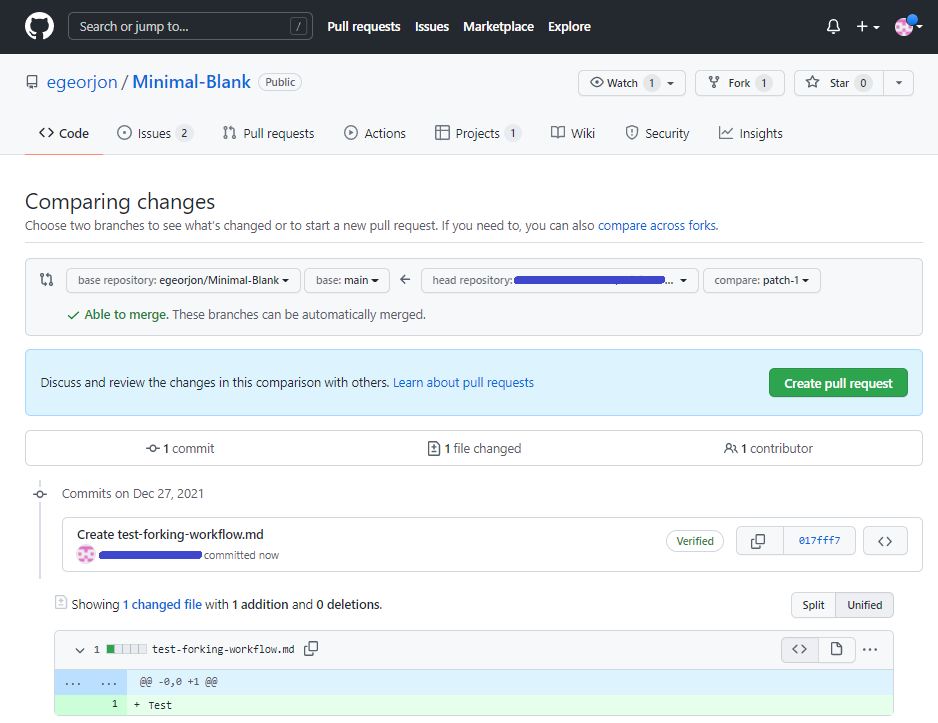
Pour demander l’incorporation de ce fichier dans le dépôt de référence, je crée un pull request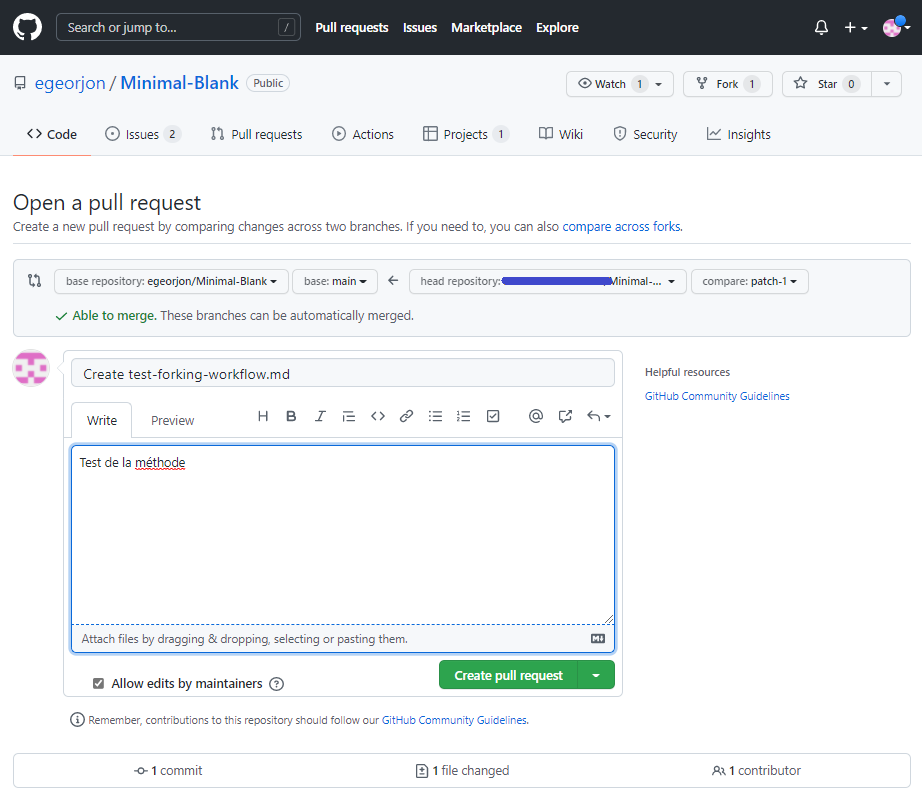
Le pull request vient d’être ouvert. Il apparaît dans le dépôt de fork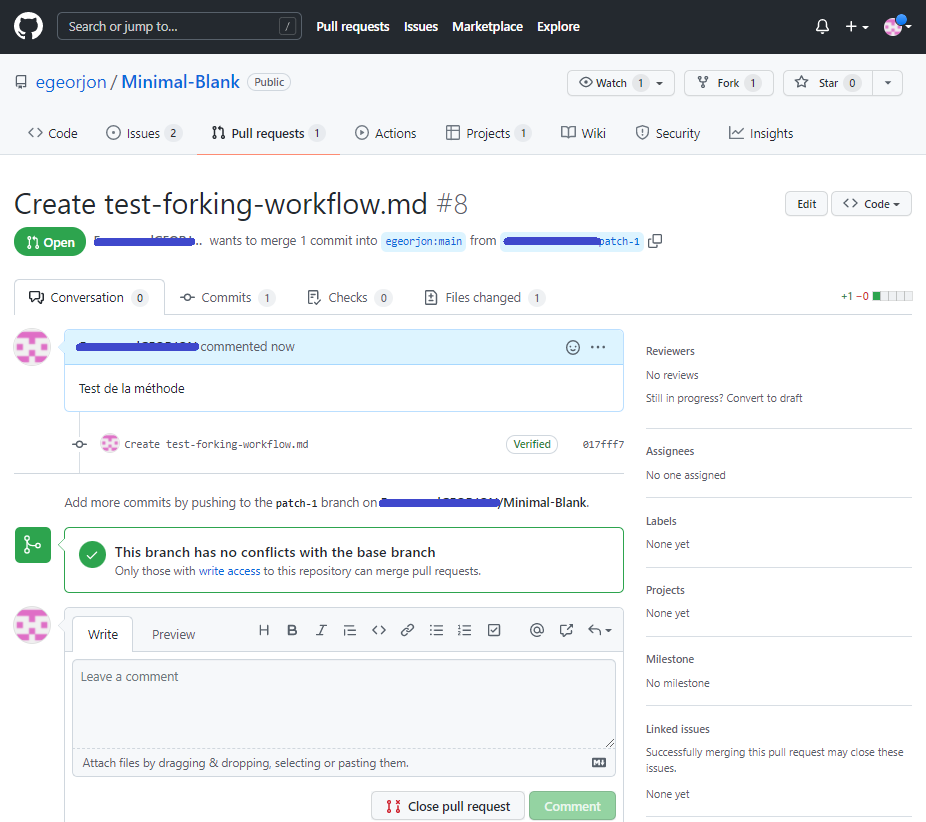
Le pull request apparaît également dans le dépôt de référence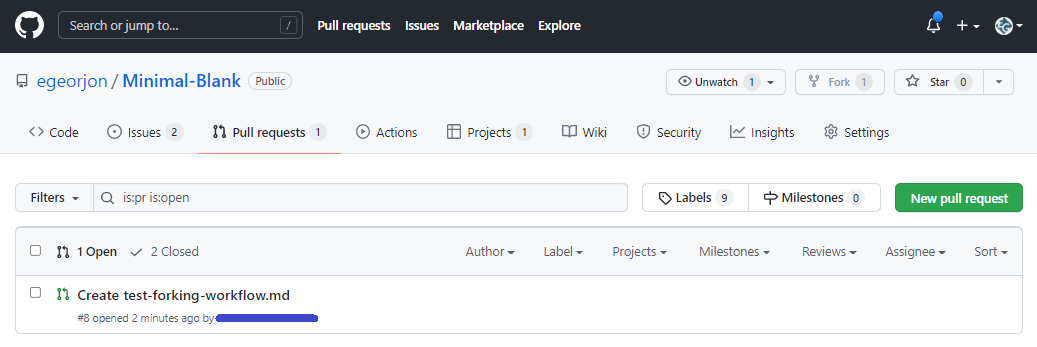
Motivation
Comme je l’ai déjà expliqué, la méthode Forking permet de contribuer à un projet, sans avoir les droits sur le dépôt correspondant. Elle permet un contrôle strict des modifications du code. Cette méthode est surtout utilisée dans le cadre de projet opensource.
Conclusion
La comparaison des différentes méthodes fait l’objet de nombreux débats. Pour ma part, je ne ferai pas de comparaison, parce que je n’ai pas encore assez de recul sur le sujet. Je ferai simplement quelques commentaires.
En mettant à part la méthode Forkflow très spécifique,
- Le choix d’une méthode ou d’une autre dépend beaucoup du contexte (application/solution à développer, type de projet, nombre et taille des équipes),
- Quels que soient les arguments des uns et des autres, à la fin, toutes les méthodes utilisent le même outil, et les mêmes séquences:
git pull,git add,git commit,git push,pull-requestet/ougit merge. Les développeurs font donc face aux mêmes problèmes. - Les questions portant sur les fréquences de commits, et sur les difficultés de merge sont assez subjectives et dépendent beaucoup de la discipline des équipes. Avec la méthode TBD (Trunk-Based), rien ne garantie qu’un développeur « pousse » son code suffisamment régulièrement pour éviter les problèmes de merge, et réciproquement, avec la méthode GitFlow, rien n’empêche un développeur de faire des branches courtes, et de délivrer du code à fréquence élevée.
Pour moi, le choix d’une méthode ou d’une autre se base, avant tout, sur des considérations d’organisation:
- Nombre et taille des équipes: plus le projet est imposant, plus il faut de la coordination,
- A quel « moment » veut-on gérer les conflits de fusion ?
- Quel contrôle veut-on mettre en place (pull-request, ou pas, à quel moment)?