Table des matières
La version de GIT utilisée pour construire les exemples est la 2.31.
Création d’un dépôt
Avec GIT, nous avons deux méthodes principales pour créer un dépôt
- Créer un dépôt local vide,
- Création d’un dépôt local à partir d’un dépôt distant
Il existe une troisième méthode basée sur les sous-modules (submodules), que nous verrons ultérieurement, dans l’épisode 5.
Méthode 1 : Création d’un dépôt local vide
Cette méthode s’exécute en deux étapes. L’étape 1 consiste à créer le dépôt.
| |
Ultérieurement, dans l’étape 2 nous pouvons “relier” le dépôt à un dépôt distant.
| |
<nom court> représente le nom court que vous utiliserez ensuite pour manipuler le dépôt distant.
La commande git init créé un répertoire .git qui va constituer notre dépôt local.

Méthode 2 : Création d’un dépôt local à partir d’un dépôt distant
Avec cette méthode, on se base sur un dépôt distant pour créer notre dépôt local. Il s’agit de LA méthode recommandée pour démarrer un projet “vide”. Le dépôt distant peut être GitHub , Gitlab , Framagit , d’autres serveurs publics, ou votre propre serveur. Nous y reviendrons dans l’épisode 4.
Les opérations sont donc les suivantes :
- Création et configuration d’un dépôt distant (sur GitHub, dans notre exemple)
- Puis sur votre machine, utilisation de la commande
git clone.
La commande git clone va créer le dépôt local, puis télécharger le contenu du dépôt distant.
| |

Flux de développement
Ou suis-je ?
Comme je l’ai dit dans l’article précédent, l’important lorsque l’on débute, est de savoir où nous sommes : dans quelle branche, et dans quel état se trouvent nos fichiers. Nous avons pour cela, la commande git status
Avant de démarrer, rappelons d’abord, les différents états des nos fichiers :
- Non-suivis (untracked) : ces fichiers ne sont pas suivis par GIT, et ne peuvent donc pas être manipulés par l’outil,
- Suivis (tracked) : GIT est capable de détecter chacune des modifications de ces fichiers (grâce à un mécanisme de checksum),
- Modifiés (modified/dirty) : on retrouve ici, l’ensemble des fichiers qui ont été modifiés, mais qui n’ont pas encore été placés
- Indexés (staged) : Il s’agit de fichiers qui ont été modifiés, et placés dans une zone particulière que l’on pourrait appeler zone de transit (staging area), en attente de validation (commit)
- Validés (commited) : les fichiers validés sont dont nous souhaitons figer / conserver les modifications.
GIT, au fil du processus, place ces fichiers dans 3 zones :
Situation de départ
Démarrons avec l’arborescence suivante :
| |
Nous n’avons qu’une seule branche, et nous venons de faire un commit.
| |
Le résultat de la commande correspond au schéma de la Figure 6. Les messages sont en général assez clairs :
- nothing to commit veut dire que nous n’avons aucun fichier dans l’index,
- working tree clean veut dire que nous n’avons aucune modification en attente d’indexation.

Modifications
Effectuons quelques modifications, et regardons ce que donne la commande :
| |
La commande nous dit
- Le fichier
file1.txtest un fichier suivi (tracked), modifié, mais pas encore indexé (Changes not staged). - Le fichier
file2.txtest nouveau (puisque nous venons de le créer), il n’est donc pas encore suivi par GIT (untracked). - Nous avons également une information importante : On branch main. La commande
git statusnous donne en effet la branche dans laquelle nous travaillons.
Ce qui correspond à la Figure 7
Indexation et validation
L’indexation d’une modification se fait grâce à la commande git add :
| |
L’utilisation de git add nous donne un nouveau status
- Notre fichier
file1.txtqui était suivi, mais non-indexé précédemment (Changes not staged for commit), est maintenant suivi et indexé (Changes to be committed), file2.txtest toujours non-suivi (untracked).
Les fichiers modifiés, et non indexés sont en rouge, les fichiers indexés sont en vert (désolé pour la colorisation syntaxique un peu limitée ici).
Continuons :
| |
Les deux fichiers sont maintenant suivis et indexés (ils apparaissent en vert dans le résultat de la commande).
Vérifications des modifications
Avant de valider les modifications, il peut être utile d’effectuer une dernière vérification :
- S’il s’agit d’un site, ou d’une application, nous pouvons vérifier que le site ou l’appli fonctionne correctement,
- Nous pouvons faire une relecture du code,
- Nous pouvons utiliser des commandes GIT pour vérifier les modifications effectuées.
Par exemple, nous pouvons utiliser la commande git diff :
| |
Que nous indique le résultat de la commande :
- Dans le fichier
file1.txt, nous avons remplacé lea, parle leb(-a +b). Le-a, indique que GIT considère qu’il s’agit d’une suppression. - Dans le fichier
file2.txt, nous avons ajouté lex
Le bilan de la commande correspond donc à 2 insertions, et 1 suppression. Nos fichiers sont indexés, nous venons de les vérifier, nous pouvons donc maintenant valider les modifications.
Validation des modifications (commit)
La validation des modifications consiste à les « figer » dans notre dépôt GIT. Nous utilisons pour cela la commande git commit.
| |

Quelques explications :
[master 37b4a83]indique que le commit a eu lieu dans la branchemaster, et que l’identifiant du commit est37b4a83,2 files changed, 2 insertions(+), 1 deletion(-)nous indique que 2 fichiers ont été modifiés, et que les modifications ont consisté en 2 ajouts, et une suppression, ce qui correspond au résultat de la commandegit diffutilisée précédemment,create mode 100644 file2.txtnous indique que le fichierfile2.txtest un nouveau fichier dans le dépôt
Les “commits”
Un peu plus haut, j’ai dit que le “commit” consistait à pousser dans le dépôt, les modificatons présentes dans l’index. Ce n’est pas tout à fait exact : un commit est un instantané de l’index. Hors l’index, comme notre répertoire de travail, ne contient pas que les modifications que nous venons de faire. Il contient l’ensemble des fichiers et répertoire de notre projet (comme le montre la Figure 9).
Donc un commit est une sauvegarde, ou un instantané de notre projet à un instant t.
Même si, dans le paragraphe précédent, nous avons réalisé des commits pour deux modifications, notre commit contient l’état de l’intégralité du projet. Cet état est considéré comme stable.
Cette notion est importante, car elle permettra de comprendre ultérieurement, les commandes permettant de récupérer des versions anciennes de nos fichiers, ou de notre projet. La plupart du temps, ces commandes auront deux syntaxes
- Une syntaxe permettant de spécifier un fichier, pour récupérer ce fichier, tel qu’il était à un instant t,
- Une syntaxe sans indiquer de fichier précis : dans ce cas, nous récupérerons l’intégralité de notre projet.
Dès que nous sortons du flux standard, dans différentes commandes de GIT, nous devons faire référence à des commits. Nous avons déjà aperçu précédemment, des identifiants courts (7 caractères), et des identifiants plus longs.
Prenons un exemple :
| |
A chaque commit, GIT calcule « une clé » unique, qui sert d’identifiant à ce commit.
- Ces identifiants sont des chaînes alphanumériques de 40 caractères,
- Nous pouvons faire référence à un commit, soit en utilisant cet identifiant, soit en utilisant les 7 premiers caractères de cet identifiant
- Le second commit peut donc être désigné par 37b4a83,
- Le troisième commit porte l’identifiant 98052bc.
HEAD -> masternous montre deux choses :- Le commit a été réalisé sur la branche
master, le prochain commit se fera sur cette branche, HEADcorrespond au commit 98052bc
- Le commit a été réalisé sur la branche
Pour éviter de devoir retenir ou copié/collé ces identifiants, GIT nous propose des raccourcis. Nous pouvons désigner un commit, par rapport à sa position relative à HEAD :
HEADdésigne le dernier commit,HEAD~1est l’avant dernier (le père de HEAD),HEAD~2est l’avant-avant dernier (le grand-père),- … …
Une autre façon de désigner un commit, consiste à utiliser les références données par la commande git reflog
| |
Des commits atomiques
Dans l’exemple précédent, nous avons réalisé un seul commit pour les deux fichiers en même temps. En fait, un commit peu contenir autant de modifications que nous le souhaitons. Nous pouvons choisir de faire des commits :
- après chaque modification de chaque fichier,
- après une journée complète de travail.
Dans le second cas,
- Nous n’aurons qu’un seul message / qu’une seule description pour l’ensemble de nos très modifications,
- Si nous souhaitons revenir en arrière, par exemple, revenir à l’état de notre projet lors du commit précédent, nous ferrons un bon en arrière de 24h.
Donc, la fréquence de commit est importante : les deux cas que j’ai donné sont probablement excessifs. La définition d’un “bon” commit est généralement :
- Le commit ne concerne qu’une chose et une seule,
- Il doit contenir un ensemble réduit et cohérent de modifications.
C’est ce que l’on appelle des commits “atomiques”.
Deux exemples vécus :
- Lors de l’écriture de cet article, j’ai eu l’idée d’ajouter la notion de table des matières au thème. En même temps, je suis revenu corriger quelques points de l’épisode 1. Si j’avais effectué toutes ces modifications en même temps, mes commits auraient donc contenu les modifications de cet article, de l’épisode 1, et de mon thème. Si, à un moment donné, je veux revenir sur le travail effectué pour cet article, je vais retrouver également les autres modifications. La bonne approche dans ce cas, sera de faire des commits différents pour cet article, pour l’épisode 1, et pour le thème (et de gérer cela dans des branches différentes, comme nous le verrons dans l’épisode 3)
- En parallèle de l’écriture de cet article, j’ai mis en place la gestion de cookies. Cette opération a nécessité environ 1 heure de travail, la création d’un fichier, et la modification de 3 autres. Je n’ai fait qu’un seul commit. Ces modifications ne concernaient qu’un seul sujet, le nombre de modifications étaient limitées, et ces modifications étaient cohérentes les unes par rapport aux autres.
Si je reprends l’exemple du paragraphe précédent, cela donnerait les opérations suivantes :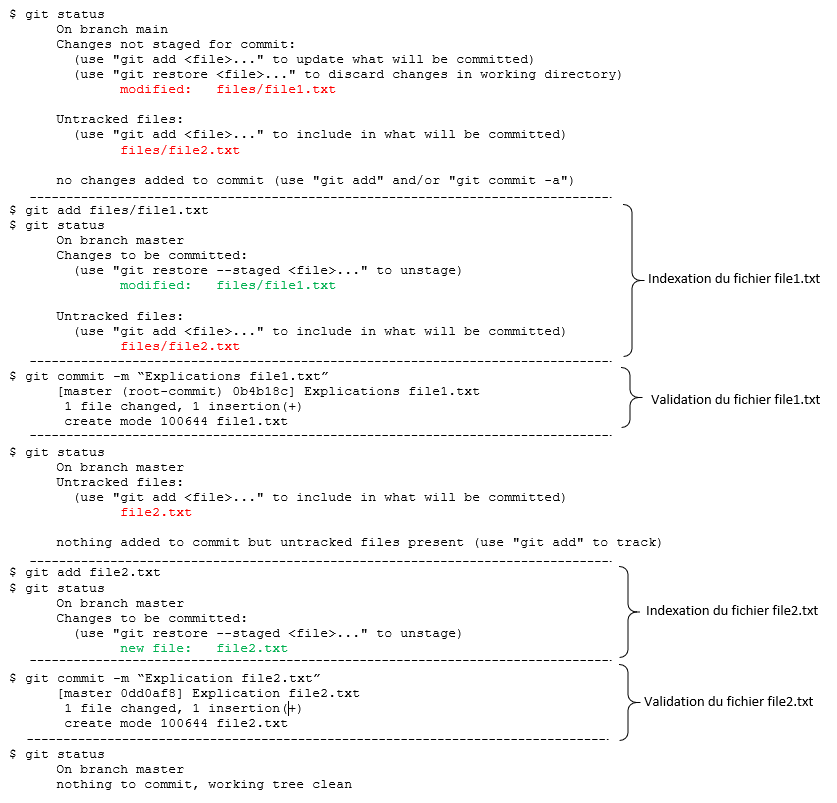
Cette notion de commit atomique est particulièrement importante si vous travaillez en équipe. Car cette approche permet de garder une bonne traçabilité de vos modifications. Vos collègues pourront donc mieux comprendre ce que vous avez fait, ou voulu faire, et la reprise éventuelle de votre travail en sera facilité.
Raccourcis et corrections
Il est possible d’indexer, et de valider des fichiers en une seule commande
| |
La commande est équivalente aux deux commandes git add <nom du fichier> et git commit -m < commentaire >.
Si nous voulons modifier le commentaire à postériori
| |
Si nous avons oublié un fichier dans le précédent commit, nous avons le choix de
- Effectuer un nouveau commit pour le fichier oublié,
- Utiliser l’option
--no-editpour inclure le fichier manquant dans le dernier commit
| |
Sortir du flow standard
Jusqu’à présent nous avons travaillé avec un flow « idéal » (edit > add > commit). Mais que faire en cas d’erreur ?
- Nous avons fait une ou plusieurs modifications de nos fichiers, et nous sommes dans une impasse,
- Nous avons effacer une partie du code d’un fichier.
Pour ce genre de problème, nous avons plusieurs commandes à notre disposition :
- Des commandes pour savoir où nous en sommes :
git log,git diff, en plus de la commande déjà vuegit status - Des commandes pour « récupérer » des fichiers ou revenir en arrière :
git checkoutetgit reset
Connaître le status
Reprenons notre exemple, dans l’état de la Figure 8 :
- Nous avons deux fichiers
file1.txten version 2, etfile2.txten version 1 - Le fichier
file2.txtcontient la lettrex
Avant d’engager les actions pour corriger notre erreur, il est important de faire le point. Nous avons pour cela trois commandes, déjà vues dans les exemples précédents :
git statuspour connaître la position de nos fichiers dans les différentes zones,git diffpour détecter les modifications effectuées,git logpour repérer les commits réalisés précédemment, et comprendre l’historique.
Je ne reviendrai pas sur la commande git status, dont les résultats ont déjà été abordés.
Regardons de plus près notre commande git diff
| |
La commande nous donne, à chaque fois, le même type de réponse :
| |
La commande git log nous aide à comprendre l’historique de notre développement.
| |
Ici, nous avons deux validations, avec leur description. Ce résultat permet, par exemple, de capturer les identifiants des commits. Certaines options nous donnent plus de détails :
| |
ou au contraire, moins de détails :
| |
Pour avoir tous les détails d’un commit en particulier, nous avons également la commande git show :
| |
Maintenant que nous savons ou nous en sommes, abordons les changements proprement dit.
La commande git restore
Nous avons indexé des modifications, mais après quelques tests, ces modifications s’avèrent erronées.
| |

git restoreLa commande git checkout < commit > < fichier >
La commande git checkout utilisée avec commit, et fichier permet également de faire un retour arrière dans notre zone de travail.
| |

git checkout < fichier >Exemple :
| |
La commande git checkout < commit > <nom de fichier> va, pour le fichier spécifié :
- Garder la référence HEAD là où elle se trouve,
- Ne pas toucher à la zone staging,
- Mettre à jour le répertoire de travail à partir de la zone de staging, si elle existe, sinon depuis le dépôt,
- Ecraser les modifications en cours.
La commande git checkout commit
La commande
checkoutcomporte de multiples syntaxes, et le comportement de la commande est différent en fonction de ces syntaxes. Attention donc aux paramètres utilisés.
Contrairement aux commandes précédentes, git checkout utilisée avec commit comme seul paramètre, n’intervient pas au niveau d’un fichier précis, mais au niveau d’un commit, donc sur l’ensemble des fichiers correspondants à l’état dans lequel se trouve le dépôt au moment du commit.
git checkout < commit > va, pour l’ensemble des fichiers
- Déplacer la référence HEAD,
- Mettre à jour les deux arborescences de la zone de staging et du répertoire de travail,
- Si des modifications ont été faites dans le répertoire de travail, elles ne seront pas écrasées : la zone de travail résultante, regroupera l’ensemble des modifications existantes dans la zone + les modifications correspondants au commit.

Dans le cas de la Figure 12,
- Nous avons réalisé des modifications, et nous les avons validé (v3),
- Mais nous souhaitons repartir de l’étape précédente, car les résultats de la v3 ne sont pas satisfaisant.
- En effectuant un
git checkout HEAD~1, nous allons retrouver l’ensemble du code que nous avions au moment ou nous avons validé les modifications de la v2.
La commande ne fonctionne pas si les modifications ne sont ni indexées, ni validées :
| |

L’utilisation de la commande est donc limitée à certains cas :
- Nous souhaitons retrouver des fichiers que nous avons effacé,
- Nous souhaitons faire revenir à un état stable précédent.
Revenir en arrière avec reset
La commande reset, est une sorte de synonime de la commande checkout. Elle accepte différents paramètres.
| Paramètres | Actions |
|---|---|
| git reset –soft < commit > | Déplace le pointeur HEAD vers le commit spécifié |
| git reset –mixed < commit > | (mode par défaut) Déplace le pointeur HEAD, et met à jour la zone staging |
| git reset –hard < commit > | Déplace le pointeur HEAD, et met à jour la zone staging, et le répertoire de travail |

L’état de tête détachée
Comme vous l’avez probablement constaté, les commandes checkout, et reset déplacent le pointeur HEAD, indépendamment du pointeur de branche.
Dans le cas de la Figure 16, nous avons bien le pointeur main pointant vers le code v3, et le pointeur HEAD pointant vers le code v2. Si nous travaillons ensuite à partir de là, en effectuant des commits successifs, nous voyons apparaître une dérivation, qui n’est rattachée à aucune branche. Cet état est appelé tête détachée.

Nous reviendrons sur cet état, lorsque nous aborderons les branches.
De la théorie à la pratique
Si les paragraphes précédents semblent compliqués, c’est parce que nous avons abordé les cas d’usage généraux des commandes. Dans la pratique, il suffit de retenir quelques cas :
| Actions | Commande |
|---|---|
| Annuler les modifications effectuées dans le répertoire de travail | git checkout <nom du fichier> |
| Annulation des dernières indexations | git reset --mixed |
| Annulation des dernières indexations et des dernières modifications | git reset --hard |
Conclusion
Avec cet épisode, nous sommes réellement entrés dans le sujet. Nous venons de voir les principales commandes GIT pour travailler dans un dépôt local. Les principaux points à retenir sont :
- Le status des fichiers (non-suivis, suivis, indexés, commités), ainsi que les trois zones d’un dépôt local,
- Les commandes permettant de comprendre ou nous sommes :
git status,git diff,git log - Les commandes de gestion du code
git add, gitgit commit, - Et pour finir, les commandes permettant de corriger les erreurs potentielles :
git reset, etgit checkout
Comme vous avez pu vous en rendre compte, GIT est extrêment flexible, et permet énormement d’opérations. Nous avons parfois plusieurs commandes possibles, pour obtenir le résultat. Cette flexibilité a un prix : la compléxité.
- Suivre un flux standard est assez facile,
- Avoir la rigueur nécessaire pour ne pas faire d’erreur est déjà plus compliqué,
- Savoir corriger ces erreurs nécessite une certaine maîtrise.
Je conseille fortement d’effectuer des tests dans des dépôts « jetables », pour bien maîtriser les commandes checkout, et reset. Si vous avez des corrections à faire, je conseille également de dessiner ce que vous voulez faire (avec les commits, les branches, …), car cela vous permettra de mieux suivre ensuite, les opérations à réaliser. Au fil du temps, avec l’habitude, l’utilisation de ces commandes deviendra plus naturelle.
Prochain épisode : les branches.