Les branches
Globalement, créer une branche, c’est créer une nouvelle trajectoire, isolée de la branche principale. Les branches peuvent être utilisées pour
- Paralléliser le développement de plusieurs fonctionnalités (et éviter que le développement de l’une n’interfère sur l’autre),
- Démarrer un développement exploratoire, dont l’issue est incertaine,
- Ou corriger un bug,
- Organiser le travail d’équipes de développement.
Les branches constituent l’une des fonctionnalités les plus importantes de GIT. Nous avons 5 principales opérations sur les branches
- Liste des branches existantes,
- Création d’une nouvelle branche,
- Changement de la branche active,
- Fusion de deux branches,
- Suppression d’une branche.
Liste des branches existantes
| |
La branche « active » est celle sur laquelle pointe HEAD, autrement dit, c’est la branche dans laquelle s’effectuera le prochain commit. Elle est indiquée par la couleur verte, et par le préfixe *.
Création d’une branche
La syntaxe est simple :
| |
L’outil alerte si le nom de la branche existe déjà.
La commande
git branch <branche>créé une branche, mais ne la rend pas active.
Dans la figure 2, nous avons bien une branche qui vient d’être créée, mais le pointeur HEAD pointe toujours sur le dernier commit de la branche principale.
La création d’une branche se fait à partir de la branche sur laquelle nous nous trouvons. Dans la figure 1, la branche
branche3n’est pas issue demain, mais bien debranche2.
Changement de la branche active
La commande checkout
La syntaxe est la suivante : git checkout <nom de la branche>. Exemple :
| |
Nous retrouvons donc la fameuse commande checkout, cette fois, avec une troisième syntaxe. Au passage, cela permet de revenir à la définition d’une branche : une branche selon GIT est une étiquette qui pointe vers un commit. Voilà pourquoi nous retrouvons cette commande checkout qui permet de déplacer le pointeur HEAD, d’un commit vers un autre.
| |
Les effets de la commande
Comme indiqué dans la figure 3, la commande checkout, dans ce cas, n’affecte pas le répertoire de travail, ni l’index (staging area). Si vous avez des modifications en cours, la commande le rappellera (ici file2.txt).
| |
Il y a une petite nuance à apporter sur ce qui vient d’être dit : la commande a un effet sur l’arborescence que vous manipulez. Si vous êtes dans une branche dans laquelle vous avez créé plusieurs répertoires, et fichiers (que vous les ayez commités ou pas), ces fichiers et répertoires disparaîtront de votre arborescence de travail, lors du checkout vers une autre branche. Ils réapparaîtront lorsque vous reviendrez sur cette branche.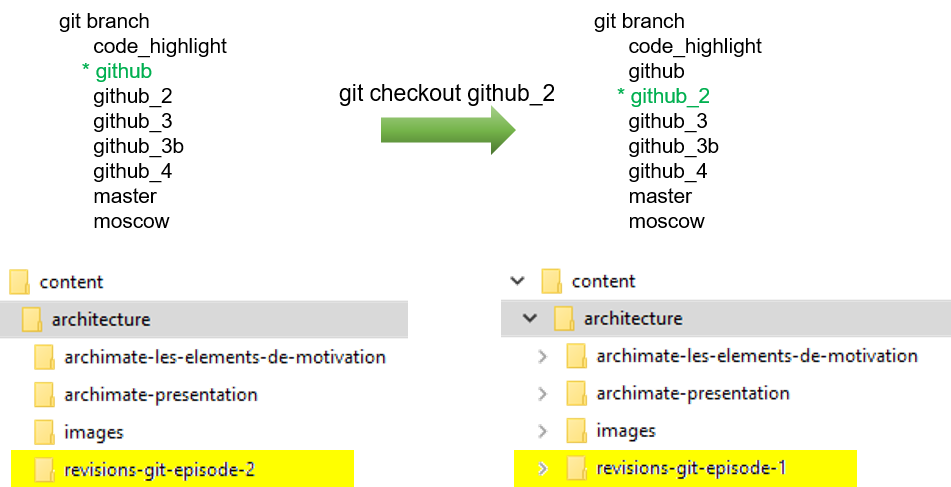
Donc
- Si vous êtes dans une branche A, et que vous modifiez un fichier dans un sous-répertoire qui n’existe pas dans une branche B
- Si vous passez à la branche B, le répertoire disparaîtra, et votre modification avec.
Heureusement, la commande le signale :
| |
La commande stash
Dans le cas que nous venons de décrire, nous souhaitons changer de branche, mais les modifications en cours nous en empêchent. Il nous faut valider (commit) ces modifications pour être autoriser à changer de branche. Mais que faire si nous ne sommes pas prêts ?
GIT nous offre une solution pour ce genre de cas : la commande git stash. Cette commande permet de stocker temporairement nos modifications en cours (dans le répertoire de travail), et de les réappliquer ultérieurement.
Reprenons l’exemple précédent : nous ne pouvons pas quitter la branche feature.
| |
Une fois effectuer les changements dans la branche master, nous pouvons revenir à la branche feature, et réappliquer les modifications initiales :
| |
La commande git stash pop applique les modifications sauvegardées dans notre espace de travail, puis supprime « la sauvegarde ».
Il est possible d’appliquer les modifications, et les conserver pour les réappliquer ultérieurement, avec la commande git stash apply.
Par défaut, la commande git stash s’applique aux changements
- De la zone staging (index),
- Sur les fichiers suivis, modifiés, mais non indexés (tracked) du répertoire de travail
La commande ne s’applique ni sur les fichiers non-suivis, ni sur les fichiers ignorés, à moins d’utiliser les paramètres -u, et -a :
- L’option
-u(ou--include-untracked) inclut les fichiers non-suivis, - L’option
-a(ou--all) inclut tous les fichiers, y compris les fichiers ignorés.

Gérer plusieurs stashes
Exécuter git stash à plusieurs reprises, va créer plusieurs stashes. Ces éléments sont stockés sous la forme d’une pile LIFO (Last In, First Out).
| Commande | Description |
|---|---|
git stash list | Afficher la liste des stashes |
git stash pop | Récupère les modifications correspondant au dernier stash |
git stash save "<message>" | Sauvegarde les modifications, en annotant le stash |
$ git stash pop stash@{<numéro>} | Récupère les modifications du stash correspondant à <numéro> |
$ git stash show [-p] | Affiche le résumé d’un stash (les modifications). -p donnera tous les détails |
git stash list | Afficher la liste des stashes |
git stash clear | Supprime l’ensemble de la pile de stashes |
git slash drop <identifiant> | Supprime le stash désigné par l’identifiant |
git stash branch add-stylesheet <identifiant> | Créer une branche à partir des modifications du stash désigné par l’identifiant |
Les lignes suivantes mettent en pratique les commandes que nous venons de lister :
| |
Fusion de deux branches avec la commande merge
A un moment donné, si nous sommes satisfaits de nos modifications, nous pouvons les intégrer à la branche principale. On parle de fusion de branches (merge). Lors d’une fusion, GIT va intégrer toutes les modifications contenues sur chaque branche dans une seule et même arborescence.
Le processus de fusion habituel est
- On se place d’abord sur la branche qui va recevoir toutes les modifications,
- On effectue la fusion
- A partir de ce moment, toutes les modifications de la branche
featuresont intégrées à la branchemain.

Dans ce cas, l’opération de fusion créé un nouveau commit, qui a deux parents. Il ne remplace pas le commit courant.
Une fusion correspond à l’intégration de toutes les modifications effectuées sur les deux branches que nous souhaitons fusionner. GIT est capable d’identifier les modifications dans les différents fichiers, et de les agréger. Dans certains cas, cependant, GIT ne peut pas gérer les “conflits”, qu’il faut alors résoudre manuellement.
Pour cela GIT interrompt le processus de fusion, et ajoute des marqueurs dans les fichiers à fusionner. Nous devons éditer les fichiers manuellement afin de résoudre ces conflits.
Ce travail manuel est assez rébarbatif lorsqu’il est fait avec l’outil GIT en ligne de commande. Il vaut mieux effectuer ce genre d’opération, soit avec un outil embarqué dans votre environnement de développement, soit depuis un serveur git centralisé comme Github
.
git merge --abort ne peut être exécutée qu’après un git merge conduisant à de conflits non résolus automatiquement. Cette commande tentera alors d’annuler l’opération de fusion, et de revenir à la situation initiale. Cette tentative peut conduire éventuellement à la perte de vos modifications en cours.
Exécuter
git mergeen ayant des modifications non commitées est fortement déconseillé
Résumé
La figure 7 donne un exemple d’utilisation de deux branches simultanément.
- Création de la branche
- Comme nous n’avons pas changé de branche, les modifications sont toujours effectuées dans la branche
main - Pour développer dans la branche
featurenous devons explicitement le demander - La branche active étant maintenant
feature, toutes les modifications seront “enregistrées” dans cette branche - Mais rien ne nous empêche de revenir à la branche
main, - Et y enregistrer des modifications
Commentaire : Il ne s’agit que d’un exemple
- En pratique, il est déconseillé de développer directement dans la branche
main. On développe dans des branches, que l’on fusionne avec la branchemainà chaque fin de cycle de développement, - Et il est bien sur conseillé d’avoir des sessions de travail par branche. Si vous devez changer de branche régulièrement, vous ferez, immanquablement une erreur à un moment donné.
Retour sur l’état de « tête détachée »
Dans le chapitre précédent, nous avons parlé de l’état de tête détachée (detached head). Nous allons revenir sur cet état, et nous allons en profiter pour mieux comprendre l’utilisation des commandes log, et reflog.
Situation de départ, nous n’avons qu’une seule branche main. Dans cette branche, nous avons deux commits :
| |

Maintenant, créons la situation de tête détachée, en faisant pointer HEAD
| |
La commande nous signale la situation de façon claire.

Continuons nos modifications sur le fichier :
| |
Nous effectuons un commit
| |
Effectuons une nouvelle modification pour obtenir le commit 89cd6ad.
Si nous regardons la liste des commits avec la commande git log:
| |
Ici, nous ne voyons plus le second commit. Pour voir l’ensemble des commits, il faut utiliser la commande git reflog
| |
Au passage, notons la différence entre les commandes git log, et git reflog:
git logliste les commits relatifs à la branche en cours (donc il remonte l’historique en partant du pointeurHEAD),git reflognous donne l’historique des « mouvements » du pointeurHEAD.

git log, et git reflogmain ?
| |
Là encore, les messages de GIT sont clairs. Nous avons bien deux commits qui ne sont plus rattachés à rien.

| |
Donc là, nous avons perdus 2 commits sur les 4. La commande git reflog nous donne
| |
Pour terminer notre périple : si nous souhaitons conserver ces commits, en les identifiants clairement, nous avons la possibilité de les rattacher à une branche.
| |
Ce qui donne graphiquement :
J’ai été un peu long sur ces explications, mais je pense que c’est un cas très intéressant pour mieux comprendre la notion de pointeur, et de branche.
Avance rapide, et vraie fusion
Revenons aux fusions, en entrant un peu plus dans le détail. Précédemment, j’ai dit que la fusion créait systématiquement un commit de fusion. Ce n’est pas tout à fait vrai. Lorsque nous invoquons la commande git merge, nous avons deux cas de fusion : le fast-forward (avance rapide), et le true merge (vrai fusion).
Plaçons-nous dans la situation suivante :
- Nous avons une branche
main, avec déjà un certain historique, - Nous décidons l’implémentation d’une nouvelle fonctionnalité : nous avons créé pour cela une branche
feature, dans laquelle nous avons effectué des modifications, - Entre temps, des utilisateurs nous ont signalé des erreurs. Pour gérer la correction, nous avons donc créé une branche
patch, pour les corriger.

Le fast-forward
Notre correction étant prête, nous souhaitons l’incorporer à notre branche principale. Utilisons donc la commande merge :
| |

patch, cas d’un foast-forwardIci, le commit G est un descendant direct du commit C de la branche main. Il n’y a pas de modifications divergentes à fusionner. GIT se contente alors d’avancer le pointeur HEAD. Cette opération s’appelle un fast-forward (avance rapide), comme indiqué dans la réponse de la commande merge.
Supprimer maintenant la branche patch dont nous n’avons plus besoin.
Le true merge
Maintenant que l’application fonctionne de nouveau sans erreur, nous reprenons le fil de notre développement. Notre nouvelle fonctionnalité est prête, les modifications de la branche feature peut être incorporées à la branche principale. Si nous effectuons une fusion, nous obtenons
| |
Dans cas, GIT va réaliser une fusion à trois sources (three-way merge): le dernier commit de la branche main (G), le dernier commit de la branche feature (F), et le premier ancêtre commun (C). L’outil va créer un nouveau commit, appelé commit de fusion (merge commit), et va déplacer le pointeur head sur celui-ci.
feature, cas d’un true merge
Nous parlons dans ce cas, d’une vraie fusion (true merge). Nous pouvons maintenant supprimer la branche feature, dont nous n’avons plus besoin.
Influencer le comportement de GIT
Dans les deux cas précédents, nous avons laissé GIT décider de la statégie de fusion. Comme vous pouvez le constater avec les figures figure 16 et figure 18, appliquer l’une ou l’autre des méthodes de laisse pas le même historique. Pour diverses raisons, notamment lorsque l’on travaille en groupe, notre volonté peut être de
- Garder un historique des modifications, pour privilégier la traçabilité,
- Ou, au contraire, proposer un historique propre et linéaire pour une compréhension plus aisée.
Il est possible d’influencer la stratégie de fusion avec le paramètre --no-ff, qui comme son nom l’indique, demande à GIT de ne pas réaliser de fast-forward.
| |
Fusion de deux branches avec la commande rebase
Jusqu’à présent, nous nous sommes basés sur des exemples, où une branche de développement, issue d’une branche principale, “avance” plus vite que sa branche mère. Mais que se passe-t-il, si l’historique de la branche principale évolue régulièrement, en parallèle de notre branche de développement ?
L’exemple
Reprenons notre exemple précédent. A la fin du fast-forward, nous avons :
Lors du développement de la nouvelle fonctionnalité, nous découvrons que le patch est nécessaire au son fonctionnement.
Pour remédier à cette situation, nous pouvons considérer une fusion, non pas de la branche de feature vers la branche main, mais au contraire, de la branche main vers la branche feature, pour ensuite continuer nos développements :
et nous pouvons poursuivre le développement sur la branche feature, puis incorporer cette branche à notre branche principale (en mode true merge)
Comme vous pouvez le constater, l’historique de développement devient un peu compliqué. Comprendre cette historique avec les commandes git log va devenir extrêmement complexe.
Nous avons une autre possibilité d’intégrer le patch dans la branche de développement, en utilisant la commande rebase, dont la syntaxe est tout à fait similaire, à celle de la commande merge :
| |

La commande rebase « réécrit » l’historique de la branche en créant de nouveaux commits (E’, F’ dans le cas de la figure 22) pour chaque commit de la branche d’origine. Nous avons donc maintenant :
- Les modifications de la nouvelle fonctionnalité, incluant le patch,
- Un historique beaucoup plus propre que celui obtenu avec la commande
merge.
A partir de là, nous pouvons continuer le développement de la fonctionnalité, avant de l’intégrer dans la branche principale :
Pour résumer
La commande git rebase peut être utilisée lorsque nous sommes dans les situations suivantes :
- Certaines fonctionnalités de la branche principale sont pertinentes pour notre développement,
- La base de départ de notre branche de développement est jugée obsolète,
- Les deux branches divergent trop, et la future fusion risque d’être complexe à exécuter.
Utiliser la commande git merge est possible, mais comporte deux principaux inconvénients
- En fonction des cas, cette opération peut rendre la lecture de l’historique relativement complexe à comprendre,
- Le commit issu de la fusion des deux branches peut intégrer un grand nombre de modifications comparé à son prédécesseur, ce qui peut rendre, là encore, les choses difficiles à comprendre.
La commande git rebase permet donc d’intégrer l’historique de la branche principale, tout en conservant un historique simple.
- Les avantages
- L’historique du projet est plus propre,
- L’historique étant linéaire, il est plus facile à remonter,
- Les inconvénients
- On perd certains points de contexte : les moments de divergence, et de convergence (les merges),
- La commande peut potentiellement poser des problèmes vis-à-vis des dépôts distants (que nous verrons dans le chapitre suivant),
- La commande
mergene touche pas aux commits existants. La commanderebaseréécrit l’historique : elle peut être potentiellement dangereuse.
Suppression d’une branche
La commande pour supprimer une branche est la suivante :
| |
A noter que l’on peut également utiliser le paramètre -D qui est équivalent à -d -f (--delete --force)
feature ne sont pas effacés. Ils subsistent, et peuvent être listés grâce à la commande git reflog, qui référence l’historique du pointeur HEAD.
Stratégie de fusion et flux de travail
Avec ce chapitre, nous commençons à voir qu’utiliser GIT n’est pas qu’une question technique, mais c’est également une question de méthodologie, surtout lorsque l’on travaille en groupe, avec des dépôts distants.
Il est important de définir des conventions, et une méthodologie commune de travail sans quoi,
- Il y aura toujours un risque de perte des modifications,
- L’historique de ces modifications deviendra illisible, et la traçabilité deviendra quasiment impossible.
Conclusion
Nous venons d’aborder la notion de branche dans GIT. Nous en avons profité pour “jouer” un peu avec les pointeurs. Les épisodes 2 et 3 montrent bien ce que j’annonçais dans l’épisode 1 : bien comprendre l’outil, c’est avant tout savoir ou l’on se trouve : à la fois dans les différentes zones de stockage, et à la fois dans notre arbre de commits.
Nous allons continuer notre apprentissage de GIT, en abordant, dans le prochain épisode, les dépôts distants.